Do you remember a scene in Star Trek IV in which Scotty picks up the mouse of a 20th century computer and tries to speak through it? It was funny then, still is today. But will we still laugh in say 10 years? In case you didn’t know: Amazon lets you change the invocation word of your Echo devices to ‘Computer’ (besides ‘Alexa’, ‘Echo’, and ‘Amazon’) – a dream come true?
Thanks to BFFs Siri, Alexa, and Cortana, also the recent strides of Facebook, Microsoft, and others around text-based chatbots, the decades-old technologies involved in building natural language dialog systems are now being discussed in “mainstream” technology circles everywhere. One use case for this technology is in B2C communication, specifically in customer service and brand engagement over platforms such as Amazon Echo and Google Home, as well as Facebook Messenger, SMS, or kik. When discussing the technical approaches vendors are taking to build customer support chatbots or voicebots, differing technologies come into play and, in fact, are often mixed together.
This article aims to shed light on two of the most frequently confused steps in building a bot, i.e. an automated dialog system of any flavor: speech recognition/transcription, and natural language understanding/semantic interpretation.
Voicebots vs. Chatbots
The first clear distinction we need to make is whether we’re talking about spoken language (speech) or written language, i.e. voicebots on Alexa-like systems, or chatbots (text bots) on FB Messenger, web chat, or SMS. One takes much more time and effort to build than the other. (Note that while the English word “to chat” does not imply whether the conversation is conducted in written or spoken form, the term is typically used for text-based systems, so I’m going to use this meaning here going forward.)
Spoken language comes to life through acoustic signals. To make sense of what a user is saying you have first to transcribe their speech into text. This process is typically referred to as speech recognition, abbreviated as ASR (“Automatic Speech Recognition”). The output of this step is text. But that’s where things easily get fuzzy. The process of converting speech into text is really only a transcription step – the computer knows (“recognizes”) the words you said, but it doesn’t yet know what to do with these words.
A short detour. Back in my university days, I took 2 semesters of Korean. Korean has a writing system that looks complicated at first sight, almost like Chinese, but is actually quite straightforward as it consists of letters like our Latin system does – 24 of them to be precise. When I was in the middle of learning Korean, I learned all kinds of vocabulary. By now, 15 years later, I have forgotten most of it, but I still remember how to read and write Korean. So if I see a phrase such as 나는 당신이 이것을 번역 할 줄 알았습니다, I can read it out aloud just fine. But I have no idea what I’m saying. I don’t know the meaning of the words…
That’s similar to speech recognition (really: transcription); knowing the words that were uttered, but not knowing yet what they mean, semantically and pragmatically, i.e. what we want the computer to do with the command/utterance/response heard.
Understanding and interpreting what one heard
So, we’re missing a huge step to enable a computer to engage in meaningful dialog with us: the act of understanding what the user is saying. Once we’re in the text domain, we then need the computer to understand. That phase is referred to as natural language understanding. The output of this step is what’s called a semantic representation, or semantic interpretation.
Say you want the computer to ask about the status of your online order. You could say “where is my order”, “track my package”, “order status”, “status of my shipment”, or any other sequence of words of an almost infinite number of ways to combine words. While the variations of how to express something can be infinite, the things you want the computer to do are finite, esp. in the domain of customer service. Taking things from the spoken word to the semantic representation enables the programmer to define how the computer should respond to each of the semantic categories, e.g. what action to trigger.
It’s important to realize that when building chatbots, the entire step of recognizing speech can be skipped. The user already provides the input in text form. We therefore aren’t dealing with a step that a) requires massive computing power, and b) can produce wrong results, i.e. misrecognize words. In the text domain, “what you type is what you get.”
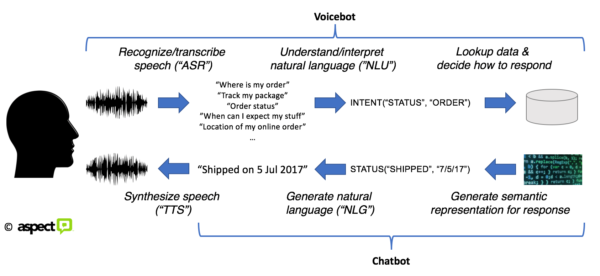
Note that in many real-world chatbot systems today, the tasks of generating a semantic representation for the response and the generation of the actual sentence are often conflated into one step.
The system that deals best with context wins
While eliminating the need for speech recognition does make things easier for a chatbot, the main challenge to build functioning bots lies in natural language understanding. It is important to understand that there is no 1:1 mapping of a sentence to a semantic representation. That has to do with contextual circumstances, linguistic knowledge, world knowledge, and dialog history. Human language is highly ambiguous.
As a simple example, consider the sentence “We saw her duck”. This could mean any of the following, and more:
- That we have viewed a certain bird that belonged to a female person?
- That we observed a female person perform the action of ducking?
- That someone with the Chinese name “We” spotted her pet?
- That we use a saw to cut her duck?
Only if you have context, e.g. knowing that previously a character by the name of “Mrs. We” was introduced, can you disambiguate this sentence.
When building a voicebot, you can consider the technology of speech recognition a commodity by now. No matter what bells & whistles, the job is clear: take a speech signal and tell me the words that were uttered. There are many vendors out there that do this job, and do it well. The reason why Siri, Alexa, and all the others are now a mass-market phenomenon is because speech recognition accuracy has reached acceptable levels. Consider this solved for the purpose of building bots. (And this is probably the most provocative statement I make in this article, as I know many will object here.)
The market leader for speech recognition is Nuance, who is behind well-known systems such as Dragon NaturallySpeaking for dictation on a PC, which has been around since the nineties, but also Siri: the speech recognition/transcription task conducted in the Apple cloud uses Nuance technology behind the scenes. Others are LumenVox, Verbio, or Interactions, but speech recognition is now also offered as a cloud service via APIs by the likes of Amazon, Google, Microsoft, and IBM.
As mentioned before, key to a successful bot is not speech recognition, but understanding and interpreting user utterances correctly. And that’s where we are still at the beginning. The most important insight here, in my mind, is that building a useful bot is more a result of good design than good technology. If you truly put yourself into the shoes of your users, think through your dialog flows and predict, for every and any response given by the bot, what the user could say or type next (based on the finite set of semantic possibilities, not choice of words!), and provide for a response or an action triggered for each of these, then you’re likely to be successful. Nothing is more frustrating than a bot responding “I’m sorry, not sure what you just said.”
The technology framework you choose for the task of natural language understanding should support you in coming up with the correct semantic interpretation of the user utterance – but the job to do the right thing as a result is still yours as the designer of the bot. The computer might simulate the “understanding” of a sentence, but it does so based on the rules you give it, whether that’s through a massive training effort using machine learning, or a massive rule-coding effort. Both approaches can help produce satisfactory results in the end.
It comes down to this: the system that deals best with context wins.
This post was originally published here.