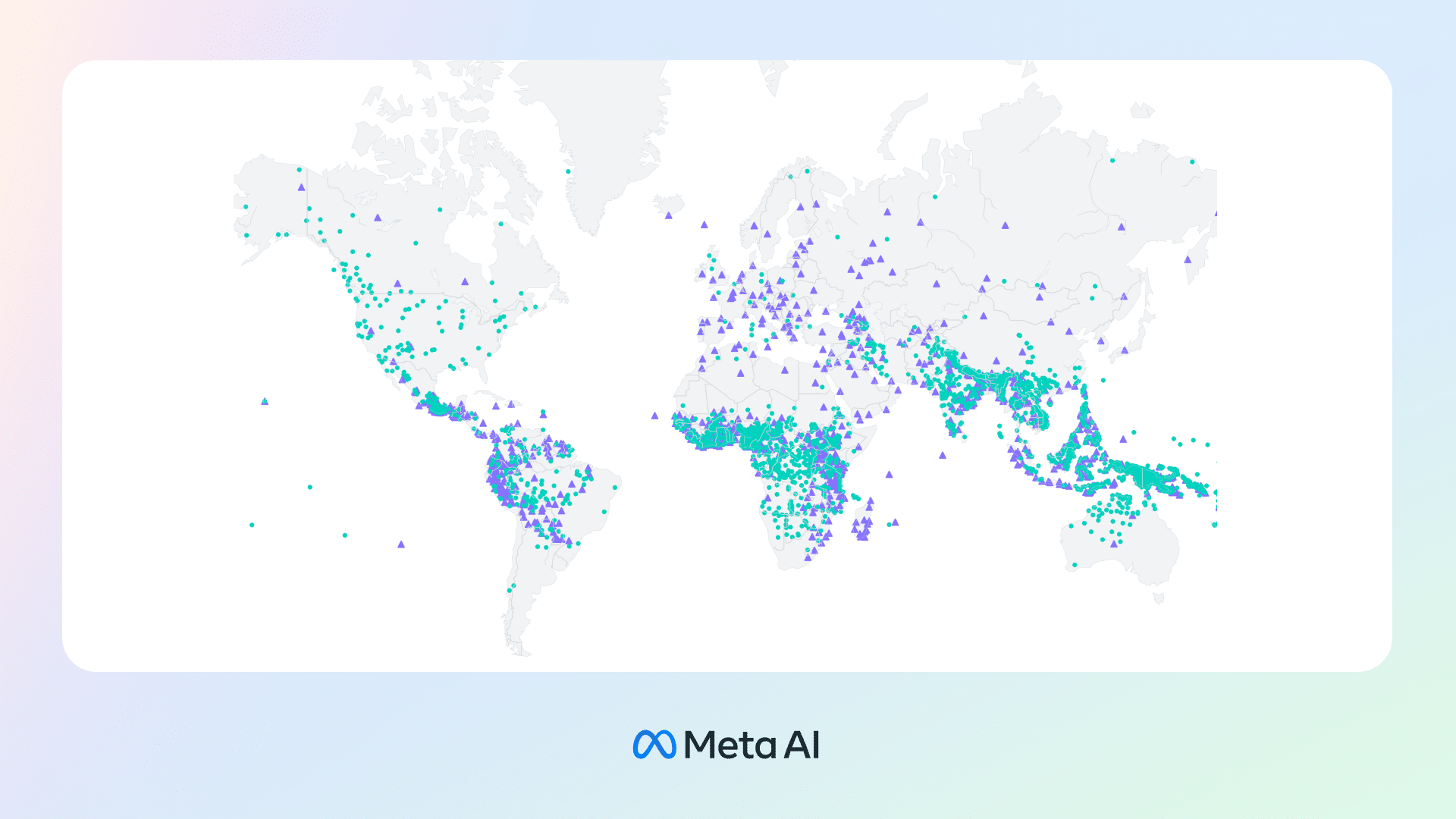
Meta has built an artificial intelligence model that has the ability to convert speech-to-text and text-to-speech for more than 1100 languages, which is 10 times more than previous models could.
Meta’s Groundbreaking MMS Model
The Massively Multilingual Speech (MMS) project can identify over 4,000 spoken languages, produce speech in over 1,100 languages, and has pre-trained models supporting over 1,400 languages.
Meta revealed this in an official statement on Monday saying that it was making the model open source so as to aid in the preservation of diverse languages which are on the brink of extinction. The company also hopes that this will aid developers of new voice apps by developers who operate in several languages, such as universal messaging services or multilingual virtual reality systems.
MMS: Massively Multilingual Speech.
– Can do speech2text and text speech in 1100 languages.
– Can recognize 4000 spoken languages.
– Code and models available under the CC-BY-NC 4.0 license.
– half the word error rate of Whisper.Code+Models: https://t.co/zQ9lWms5TQ
Paper:…— Yann LeCun (@ylecun) May 22, 2023
Meta said:
“Today, we are publicly sharing our models and code so that others in the research community can build upon our work. Through this work, we hope to make a small contribution to preserve the incredible language diversity of the world.”
Out of the 7000 languages that exist in the world, only 100 of them are comprehensively covered and understood by speech recognition models. This is due to the fact that these models call for vast quantities of labeled data for training purposes yet such amounts of data are only available for a limited number of languages.
The development of the MMS model was also faced with this challenge. To overcome it, Meta researchers retrained an existing AI model, wav2vec 2.0, which can learn speech patterns from audio without having a lot of labeled data, like transcripts created by the company in 2020.
The team also employed a new dataset that provided labeled data for over 1,100 languages and unlabeled data for nearly 4,000 languages.
“Some of these, such as the Tatuyo language, have only a few hundred speakers, and for most of these languages, no prior speech technology exists,” the tech giant said.
Using the Bible As a Dataset
To create this dataset, Meta used religious text and audio recordings as it was the most reliable source of such amounts of data in the thousands of languages.
The company said”
“We turned to religious texts, such as the Bible, that have been translated in many different languages and whose translations have been widely studied for text-based language translation research.”
The model was trained using one dataset that had unlabeled audio recordings of the New Testament in 3,809 different languages, and another that contained audio recordings of the New Testament in 1,107 different languages with their corresponding text acquired from the internet totaling over 4000 languages.
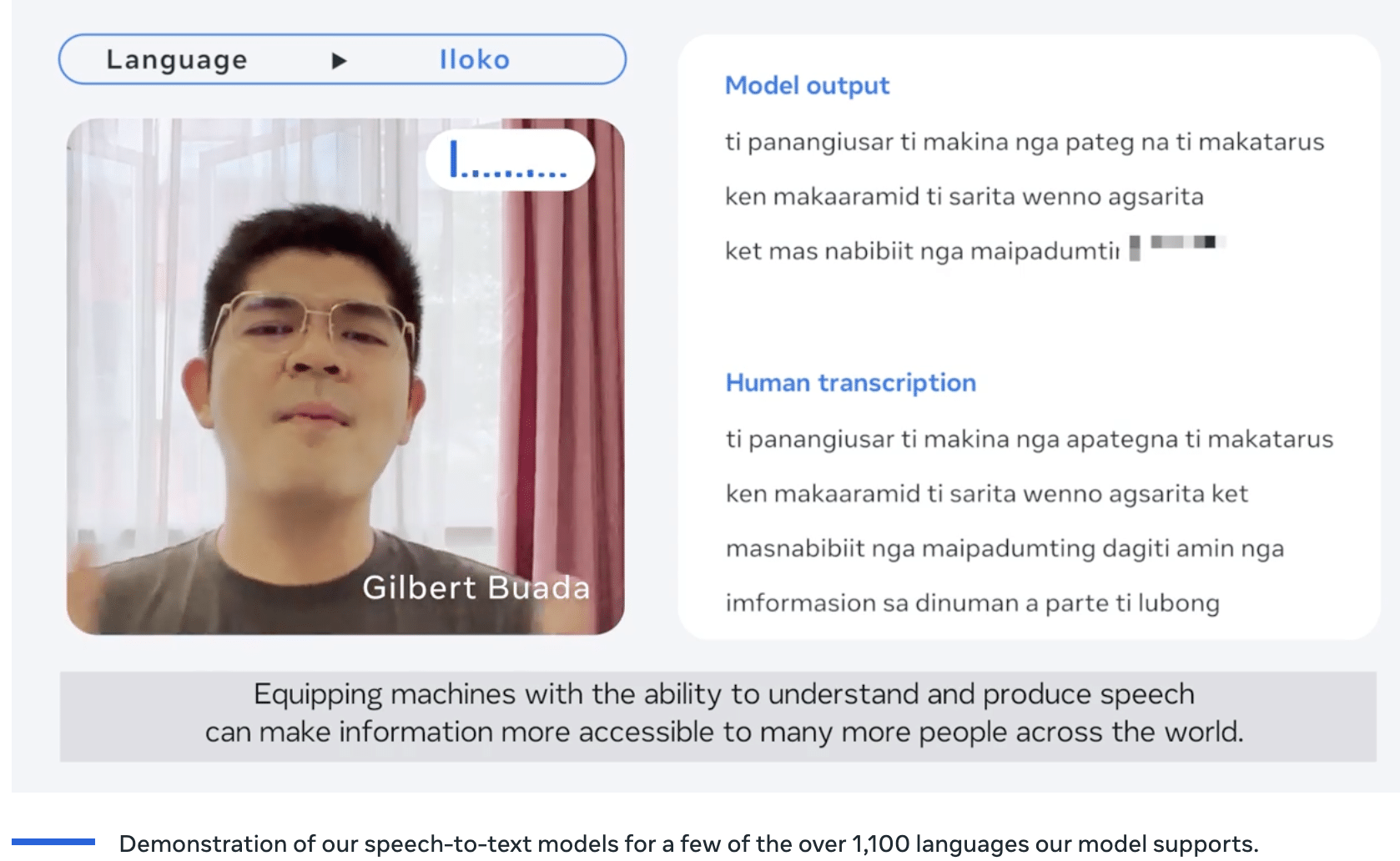
However, seeing as models are prone to biases, it is expected that the model was trained to be heavily biased toward Christian worldviews. Contrary to this expectation, Meta said that “While the content of the audio recordings is religious, our analysis shows that this does not bias the model to produce more religious language.”
When the model was tested on benchmark datasets, it was found to perform significantly better than other models while still covering 10 times more languages.
When compared to OpenAI’s Whisper, Meta stated that the model had half of Whisper’s error rate while still covering 11 times more languages.
However, as with all other AI models, MMS is equally not perfect and complete. As such, Meta issued a warning saying, “There is some risk that the speech-to-text model may mistranscribe select words or phrases. Depending on the output, this could result in offensive and/or inaccurate language. We continue to believe that collaboration across the AI community is critical to the responsible development of AI technologies.”